Routable custom data in the Delivery API

It is not entirely uncommon to see custom data entities being routed and presented as an integral part of the regular website content.
In a traditional Umbraco setup with Razor rendering, this is done using a mixture of custom routing, route hijacking, URL rewrites and content finders.
The same thing can be achieved with the Delivery API by applying a little hackery 🤓
Custom Delivery API paths
The key to all of this is the content path provider and resolver feature, which was introduced in Umbraco 13.3.
Although this feature is intended for reuse of content across multiple sites, the potential application of the feature has a far greater reach.
In this post I’ll show you how the feature can be (ab)used to route, resolve and expose custom data entities through the Delivery API.
The demo setup
To demonstrate the solution I have built an imaginary book promotion site. Or rather, I have built the content structure to serve the book site headlessly.
The setup is thought up as follows:
- Book data is imported from an external source into the Umbraco database and exposed through a service layer.
- Content editors create articles in Umbraco and cross-link relevant books using a custom book picker.
For the sake of keeping the demo complexity down I have taken a few shortcuts; the book data is hardcoded in the service layer, and the book picker is not so much a picker as it is a list of ISBNs. But neither shortcut has any impact on the purpose of this demo 😉
The content structure looks like this:
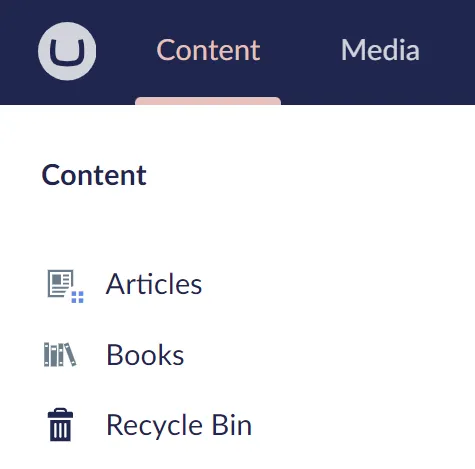
All books will be routed beneath the Books root node, to keep them easily distinguishable from the articles.
You’ll find the demo site and source code in this GitHub repo.
Routing and resolving in the Delivery API
The content path provider and resolver feature introduced two new services:
IApiContentPathProvider: Creates API request paths for instances ofIPublishedContent.IApiContentPathResolver: Resolves API request paths to instances ofIPublishedContent.
Implementing a path provider
I’m looking to extend the Delivery API - not to change the core behavior. So it’s quite practical that the core implementation of IApiContentPathProvider is public and built to be extendable 😅
An API path is really just a string that uniquely identifies a resource on the server - a Unique Resource Identifier in a nutshell.
In my thought up scenario I’m routing books, and a book by definition has a unique identifier: The ISBN. However, if anyone should end up exposing my API path in a client URL, it would be appropriate to make it SEO friendly, so I’ll combine the book name and its ISBN:
public class BooksApiContentPathProvider : ApiContentPathProvider
{
private readonly IShortStringHelper _shortStringHelper;
public BooksApiContentPathProvider(IPublishedUrlProvider publishedUrlProvider, IShortStringHelper shortStringHelper)
: base(publishedUrlProvider)
=> _shortStringHelper = shortStringHelper;
public override string? GetContentPath(IPublishedContent content, string? culture)
=> content is PublishedBook publishedBook
// NOTE: the books are routed beneath a root item ("Books"), so the API path should not include any parent URL segments
? $"/{publishedBook.Name.ToLowerInvariant().ToUrlSegment(_shortStringHelper)}-{publishedBook.Isbn13}/"
: base.GetContentPath(content, culture);
}
…where the PublishedBook is a custom implementation of IPublishedContent:
public class PublishedBook : IPublishedContent
{
// details to follow later in this post
}
Implementing a path resolver
Once again, I need to retain the core behavior. And once again, the core IApiContentPathResolver implementation is public and extendable 🤘
My path provider appends the book ISBN to the end of the path, so I’ll look for paths that end with an ISBN (13 digits):
public partial class BooksApiContentPathResolver : ApiContentPathResolver
{
private readonly IPublishedBookService _publishedBookService;
public BooksApiContentPathResolver(
IRequestRoutingService requestRoutingService,
IApiPublishedContentCache apiPublishedContentCache,
IPublishedBookService publishedBookService)
: base(requestRoutingService, apiPublishedContentCache) =>
_publishedBookService = publishedBookService;
public override IPublishedContent? ResolveContentPath(string path)
{
// is it a book path (ends with an ISBN)?
Match match = IsbnUrlPattern().Match(path);
if (match.Success is false)
{
// nope - pass it on to the core resolver.
return base.ResolveContentPath(path);
}
// yep - grab the ISBN and create the corresponding book content
var isbn13 = long.Parse(match.Groups["isbn13"].Value);
return _publishedBookService.Create(isbn13);
}
[GeneratedRegex("(?<isbn13>\\d{13})/?$")]
private static partial Regex IsbnUrlPattern();
}
The rest of the implementation
To the Delivery API, the implementation starts with the path provider and ends with the path resolver. Or vice versa 🐔🥚
Of course, there is more to it. It is however mostly plumbing. I’ll resort to briefly outlining the remainder of the implementation here - you can check it out in detail in the GitHub repo.
For starters there is the BookService that can resolve Book entities by their ISBN. As mentioned above, the service just keeps the books hardcoded, but this is where the DB access would be.
Then there is the PublishedBookService, which is responsible for creating PublishedBook instances for Book entities.
The PublishedBook is a custom implementation of IPublishedContent. This in turn yields custom implementations of IPublishedProperty and IPublishedContentType too.
None of these “published” interfaces are simple to implement, mainly because they hold a lot of state and data for rendering purposes 😰
The good news is that the Delivery API only utilizes a subset of all this state and data. To prove that point, I have purposely implemented the “published” models as bare-bone as at all possible. Methods and properties that are not required by the Delivery API have simply been omitted from the implementation.
Lastly there is the custom property editor My.Books and the accompanying value converter, which uses the PublishedBookService to turn the entered ISBNs into a collection of PublishedBook.
Putting it to the test
Enough with the techy details. Let’s see it in action 🚀
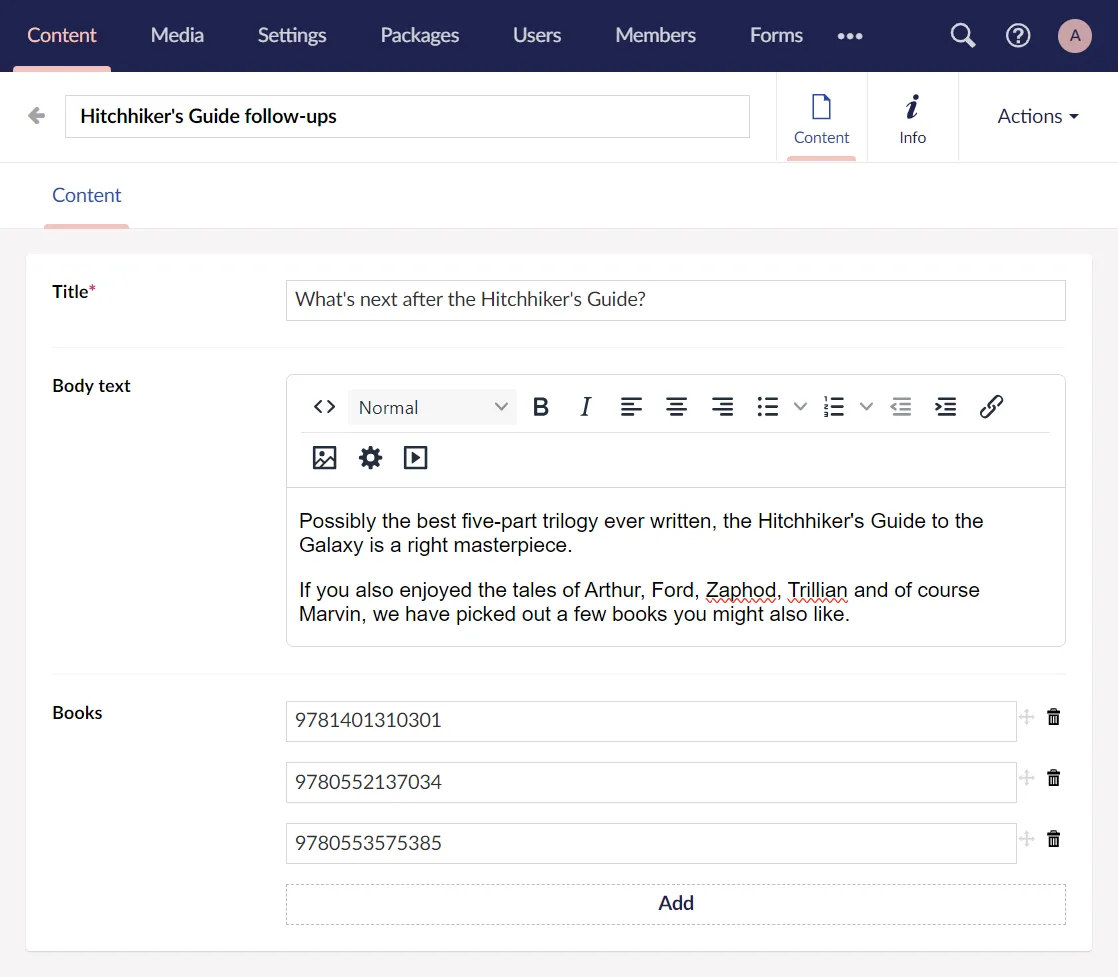
In Umbraco I have created an article about books to read after completing the awesome Hitchhiker’s Guide to the Galaxy by Douglas Adams:
Using Swagger I’ll go ahead and fetch that article through the Delivery API:
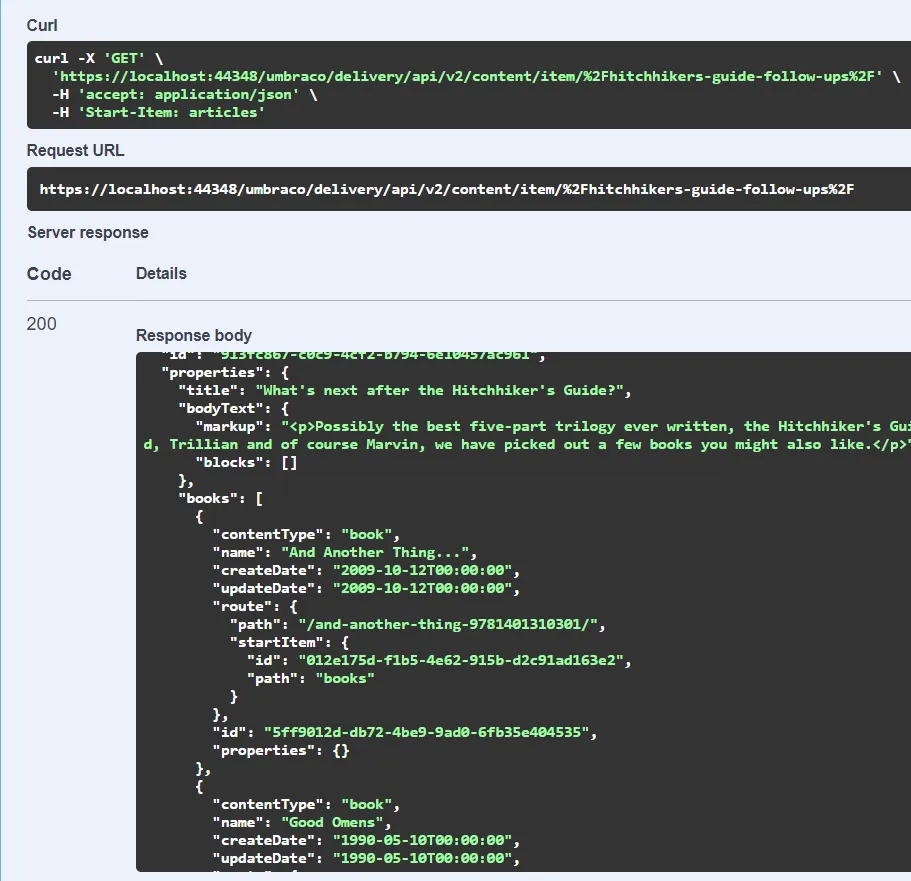
As expected, the books property renders out the collection of books in a format identical to other Umbraco content.
Likewise, books can be fetched from the Delivery API in the same manner as regular content:
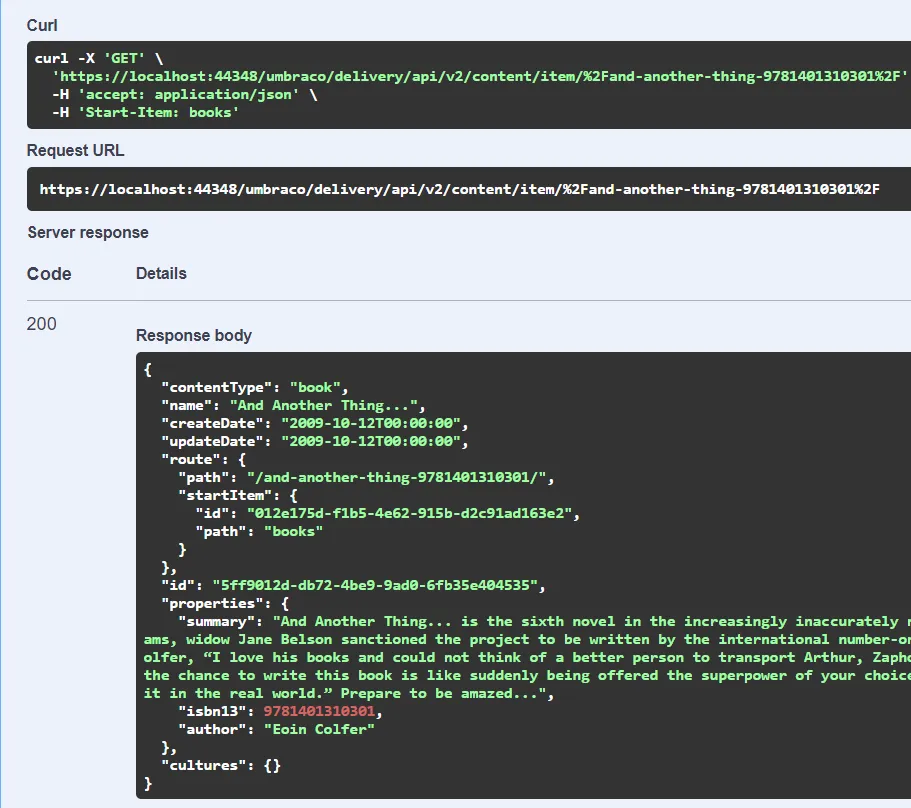
All of this works seamlessly because to the Delivery API, the PublishedBook is no different than regular Umbraco content. In turn, this means that the Delivery API will happily perform advanced queries like property expansion and limiting:
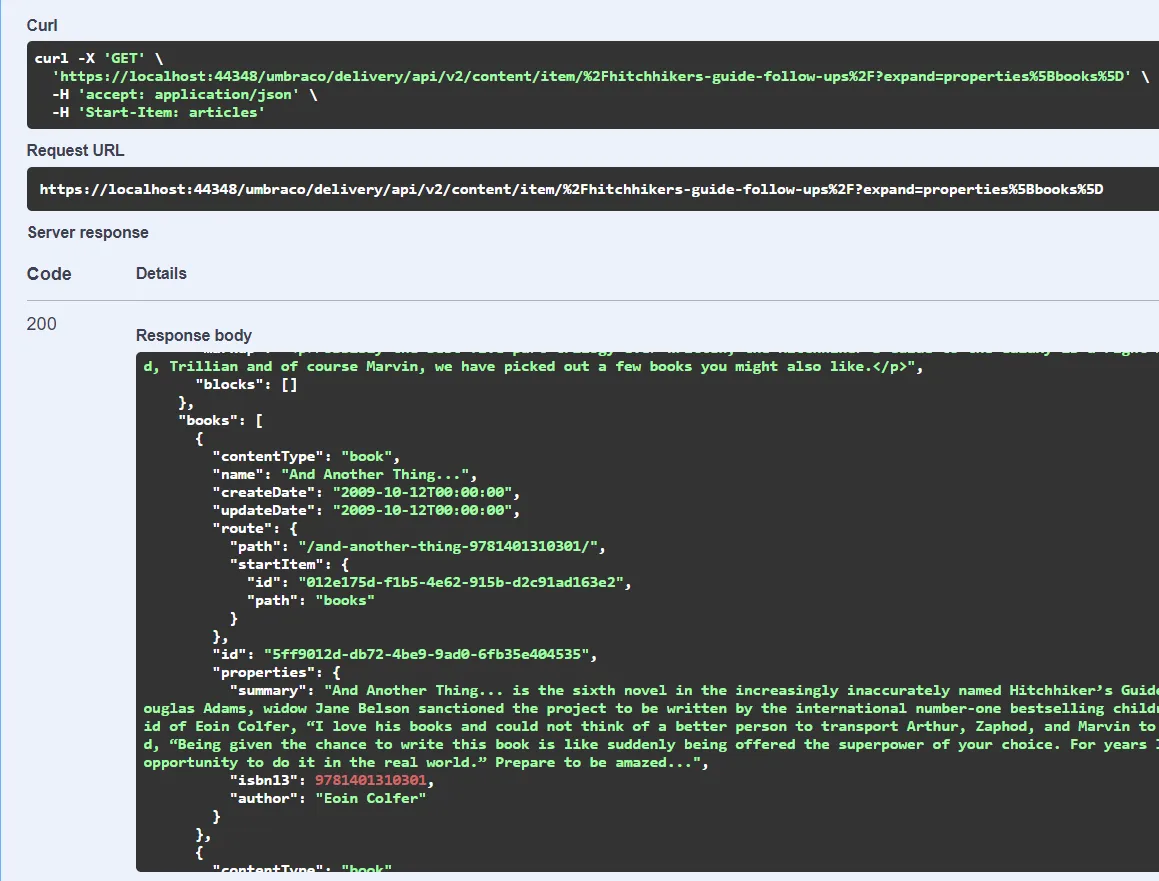
…and that is pretty darn awesome ✨🎉
Limitations
Alas, all is not peaches and cream. Routing custom data through the Delivery API is subject to the same limitations as it would be when routing it for traditional rendering:
- The books cannot be fetched by ID.
- The books cannot be searched through the “get multiple” endpoint.
The first one is not too bad - after all, the books can still be fetched by their paths.
The second one is a little more annoying. On the other hand, the built-in filtering for the “get multiple” endpoint would probably not be sufficient to create a functional books listing page anyway, so a custom filtering endpoint would likely be required regardless.
There is a silver lining, though. With all the custom “published” models in place, a custom filtering endpoint can be built with relative ease, because the Umbraco core services are readily available to perform the transformation from PublishedBook to a Delivery API shaped output.
I’ll elaborate on that in an upcoming blog post 😃
Until then - happy coding 💜